 If you are like me, you create a lot of backups. My most common backups are cutting and pasting every recognizable file that I may have created onto an external drive before routinely reinstalling Windows. This often leads to me having many copies of the same file in multiple drives and folders. I needed a way to scan for all duplicate files so that I could finally consolidate my backups into having unique files only. I decided to create a simple script that would scan two given top level directories and check each file in one directory for a duplicate in the other. If one was found, the names and locations of both files would be written to a csv file that could then be easily read and sorted in Excel. Find_Duplicates.ps1
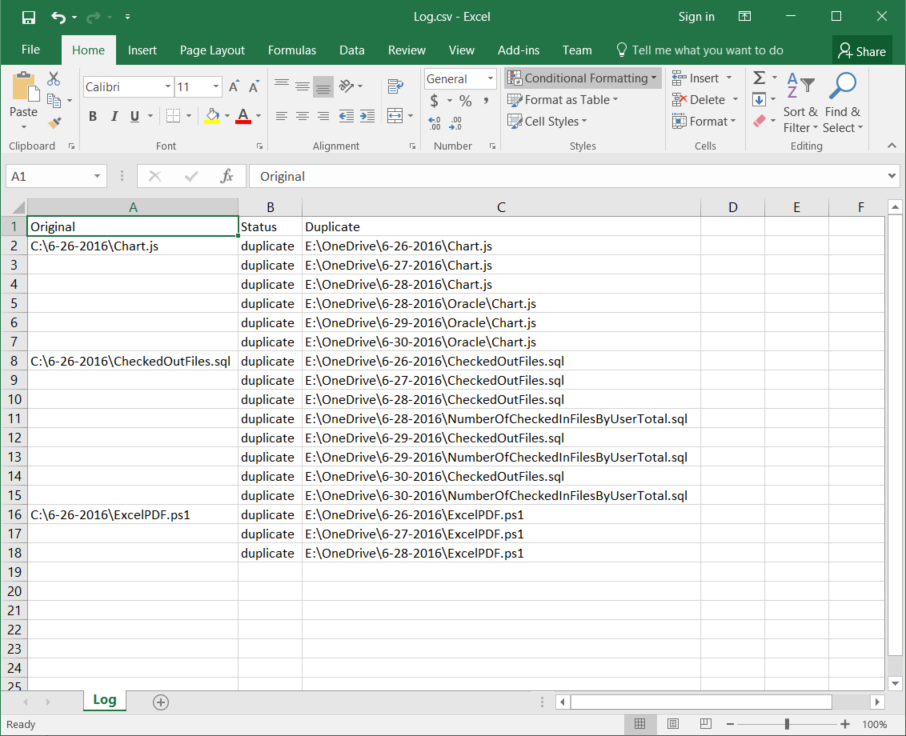
When you run the above code, you will get a Log.csv file like below if any duplicates are found. 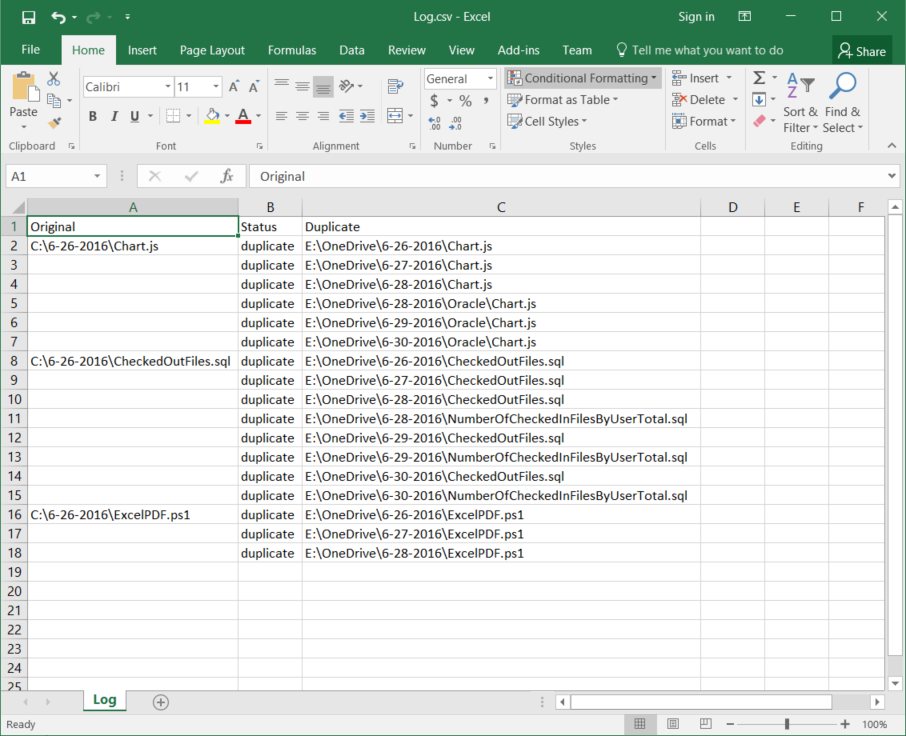 As you can see from the above example, I have many copies of the same file that even have different names. This would be a nightmare to sort out manually. The script is currently single threaded and will take some time to run on a large dataset. I plan to upgrade it to use multithreading later on and follow up with a secondary script that reads this csv file and either moves or deletes duplicates.
5 Comments
7/2/2018 08:32:03 am
Please note it is not safe to remove all the duplicates CCleaner finds. The Duplicate Finder can search for files with the same File Name, Size, Modified Date and Content; however it isn't able to determine which files are needed and which can be safely deleted. 7/2/2018 08:33:26 am
You must be aware of the fact that duplicate files in your computer can waste your precious space. There are very limited options out there to find and remove duplicate files from your computer and today we are going to share three easy methods by which you can find and easily delete duplicate files from a computer. Go through the post to know about it.
Fred
9/11/2020 03:15:50 pm
What is your variable $Off_Array ??
Bob
9/11/2020 04:12:39 pm
The logic has a couple of issues....
Tghu
11/5/2020 07:49:12 pm
Thanks for the code. I typically use CloneSpy to dedup but the do-it-yourself approach is occasionally useful for when the third-party tools fail to discriminate. Your comment will be posted after it is approved.
Leave a Reply. |
AuthorPLM engineer while "on the clock", programmer, designer, dreamer all other times. ArchivesCategories
All
|
 RSS Feed
RSS Feed